The Insides of a SIEM
The real value of a SIEM isn’t in storing data, it’s in the process of transforming, interpreting, and routing that data into something usable for security operations.

When people first hear about a SIEM (Security Information and Event Management system), they often compare it to a data lake. After all, both collect massive amounts of logs and events. But the real value of a SIEM isn’t in storing data, it’s in the process of transforming, interpreting, and routing that data into something usable for security operations.
To illustrate this, imagine a SIEM as a subway system for your security data. Each stop on the line represents a stage where raw events are processed and transformed, moving closer to their final destination: actionable security intelligence.
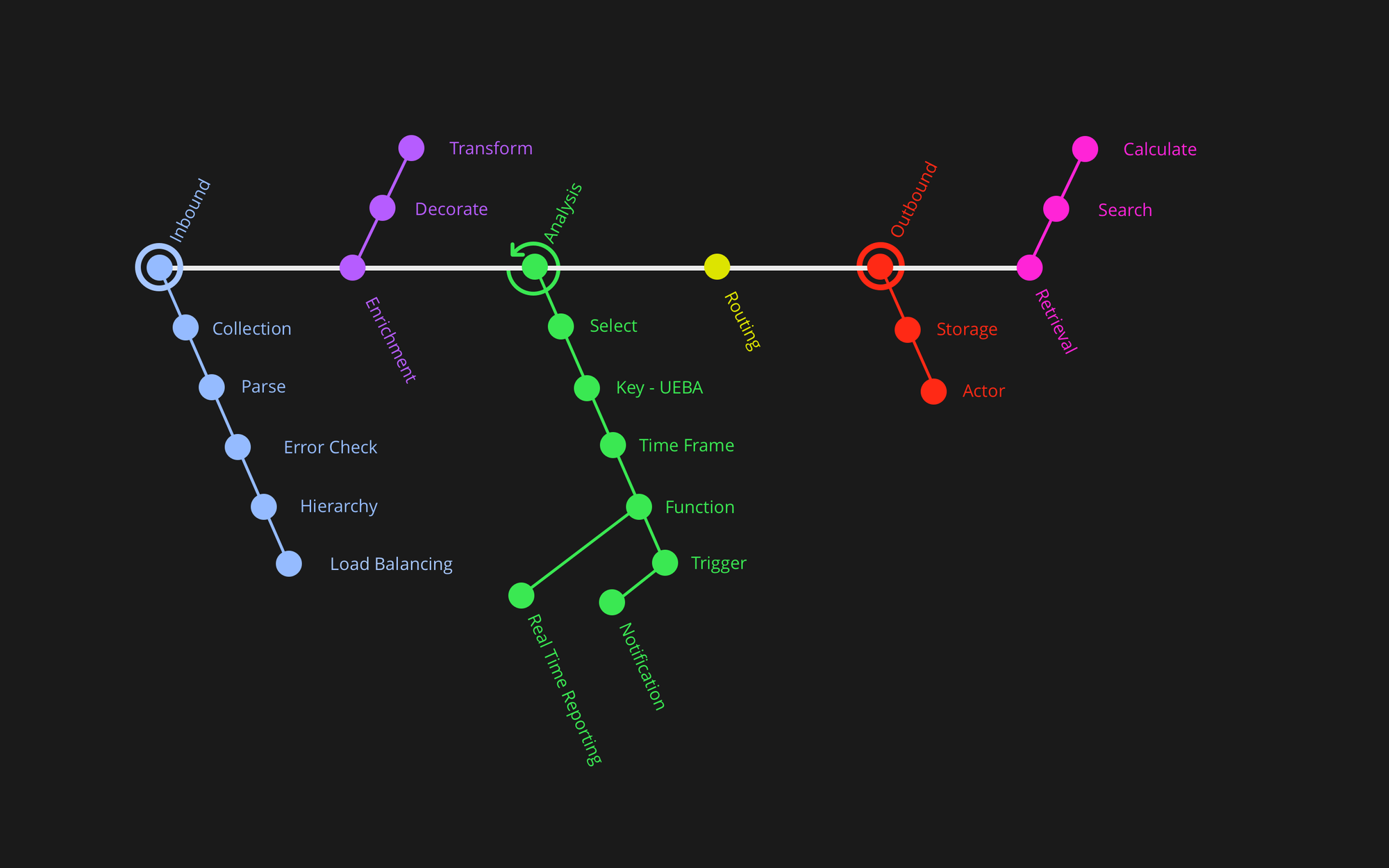
Stage 1: Ingress: Why It’s Harder Than You Think
Ingress sounds simple: collect the logs, bring them in, and move forward. But this stage is one of the hardest parts of a SIEM because the quality of everything downstream depends on what happens here.
The first challenge is how products write their logs. Every vendor designs audit data from their own perspective. That means the field names, types, and even the meanings can vary wildly. One product might call it SourceIP, another SRC_IP, another Source.IP. One system may represent an IP address as a string, another as an integer. Even categories differ, what one product calls “malicious”, another might break into “phishing, ransomware, virus.”
The second challenge is when and how logs are generated. Devices often produce events at different severity levels. Take Cisco, for example: logs can range from purely informational messages to critical alerts. That means deciding not only which logs to collect, but also how to manage the sheer volume of data that devices can produce. And even if you end up discarding some events, the SIEM must still process everything that comes in.
The third challenge is parsing correctly. At this stage, parsing isn’t about transforming data into a schema yet, that comes in Stage 2. Instead, it’s about identifying what the field is (the key) and what the field contains (its value and meaning). Sometimes this is straightforward, but in many cases it isn’t. For example, some systems output arrays of key–value pairs where half of the “data” is actually the field name itself. Ingress parsing must untangle these structures so the SIEM can capture the data faithfully before any transformation happens later.
This is why Ingress is more than just a collection step. It’s about recognizing what the data is, when it’s generated, and how to manage its volume, turning a firehose of heterogeneous inputs into reliable records that the rest of the SIEM process can build on.
Stage 2: Preparation: Making Data Usable
Once data has been collected, it is still far from ready for analysis. Logs come in raw, inconsistent, and often fragmented, shaped by the perspective of the product that produced them. Stage 2, which we call Preparation, is where a SIEM begins to turn those scattered records into something usable. This step is critical, because without preparation the analysis stage would collapse under incompatible formats and incomplete information.
Preparation begins with transformation. This is the process of reshaping logs into a consistent structure so they can be understood side by side. Every vendor writes logs differently: one may represent an IP address as text, another as a number, while a third may bury it inside a nested JSON array. If left untouched, those differences would prevent the SIEM from comparing events across sources. Transformation imposes a common frame of reference so that logs from Microsoft, Cisco, and your firewall can all describe activity in a way the system can understand.
With a consistent structure in place, the next step is decoration. Decoration means adding context that wasn’t in the original record but makes the data far more useful. An IP address by itself is just a number, but when decorated with its geolocation or tied to the asset that owns it, it tells a richer story. A username becomes more informative when linked to its department or role. Decoration doesn’t change the event itself; it adds layers of detail that sharpen the picture.
Finally, there is enrichment, which takes context one step further by connecting events to outside knowledge. This might mean checking a hash against a threat intelligence feed, scoring an IP address against a reputation database, or linking a user to identity and access management systems. Enrichment deepens the understanding of the event, turning it from an isolated data point into part of a broader security picture.
Taken together, transformation, decoration, and enrichment are not cosmetic steps, they are what make analysis possible. Unlike relational databases, most SIEMs work with document-style records that cannot support large-scale joins. That means we cannot afford to store raw logs and expect to join them later with user directories, GeoIP tables, or DNS lookups. Those relationships must be embedded into the record at the point of preparation. The same holds true in streaming analytics: constant lookups are costly, duplicative, and unscalable. By enriching the data up front, the SIEM ensures that every record already carries the context it will need. Transformation, likewise, is performed so the analytic engines can operate efficiently, focusing on selection and detection rather than reinterpreting formats. Preparation is therefore not an optional convenience, it is the only way to make data usable for real-time security analysis.
Stage 3: Analysis: Detecting What Matters
Analysis is the heart of a SIEM. This is where raw, prepared records are examined to uncover signals of risk and compromise. But it’s important to understand that analysis is not a single step. It builds in layers, moving from simple selections, to clustering by key, and finally to grouping and contextual understanding.
The first layer of analysis is selection. This is where the SIEM identifies events worth paying attention to. A selection might be as simple as, “Show me all login attempts,” or “Flag every file that matches a known hash.” At this level, the SIEM is filtering streams of data for pieces that will serve as the starting point of deeper analysis. Even something as basic as “alert when this shows up” falls into selection.
The next layer is clustering, which organizes selected events around a key, the entity they belong to. This could be a username, an IP address, or a device identifier. Clustering lets the SIEM look not just at an isolated event but at how that entity behaves over time. For example, clustering login activity by username allows the system to ask: is this the first time this user has logged in from this country? Has their authentication method changed compared to past behavior? Clustering makes it possible to compare the local history of an entity against both its own past and the baseline of the larger organization.
From here, the SIEM moves into stateful analytics. This is where time-based and behavioral techniques are applied. Instead of just flagging one login, the system evaluates gaps between logins, unusual changes in frequency, or cardinality shifts in user activity. The SIEM produces triggers when behavior deviates significantly from what is expected. At this stage, we start labeling events as “notable” or “critical.” Not every notable event is a full-blown alert, some may simply mark something worth tracking, but critical events are escalated immediately.
The final step is grouping and contextual analysis. Rarely does one event tell the full story. Most attacks reveal themselves through patterns of related activity. By grouping multiple signals together, the SIEM can create a cohesive picture. For instance, an endpoint product like SentinelOne may generate several messages: one reporting a suspicious file, another reporting that it killed the process, and a third describing the threat. If all three appear, the case is clear. But if only some of the messages arrive, perhaps the “kill” never came through, the grouping process highlights the gap. This contextual awareness, connecting events into a coherent narrative, is something individual products cannot provide on their own.
Taken together, these layers of analysis transform raw detections into actionable alerts. Selection identifies the seeds of interest. Clustering organizes them by entity. Stateful analytics apply time and behavior to give depth. And grouping pulls the pieces into a meaningful whole. The result is not just a list of alarms, but clusters of evidence that tell us something truly needs attention.
Stage 4: Routing: Directing the Flow
Once analysis has produced results, the SIEM must decide where those results go. Not every outcome deserves the same treatment. Some events demand immediate escalation. Others need to be recorded for later investigation. Still others may not warrant retention at all. Routing is the stage where the system makes those decisions and directs the flow accordingly.
An event, for example, might generate a real-time alert, an email or dashboard notification to an analyst. At the same time, it might be written into long-term storage for compliance purposes. In some cases, the event may also trigger an action, such as refreshing a user certificate, disabling an account, or forwarding the data to a partner tool. Routing is not a single action but a decision tree: one event can drive multiple outcomes depending on its importance and context.
This is where a SIEM diverges from the simplicity of a data lake. In a data lake, “routing” is little more than depositing records into storage. But in a SIEM, routing is an active process. It’s about determining how the results of analysis will be used, whether to inform humans, feed automated workflows, or integrate with external systems. Modern tools like Fluency, or even data piping platforms like Cribl, treat routing as a first-class function because it determines whether information ends up in the right place at the right time.
In short, routing is the stage that bridges analysis and action. It ensures that findings don’t sit idle but are carried to the services, workflows, and people who can use them. Without effective routing, even the most advanced detections risk going unnoticed or unused.
Stage 5: Outbound
Outbound is the simplest of the SIEM stages, but no less important. Once Routing decides where results should go, Outbound is the infrastructure that actually delivers them.
If Routing says, “Store this in the data lake,” Outbound is the mechanism that writes the record into storage. If Routing says, “Send an alert,” Outbound is the email system or notification service that transmits the message. If Routing says, “Trigger an automated action,” Outbound is the integration point with the firewall, identity system, or orchestration tool that executes it.
In this way, Outbound is not about making decisions, those were already made during Routing. Outbound is about execution. It’s the stage that ensures findings are not just identified and directed but actually arrive at the right systems and services. This is where the SIEM stops being a passive observer of events and becomes an active part of the defense infrastructure.
Stage 6: Retrieval
If the SIEM has done its job correctly, the initial analysis and alerts have already happened in real time. By the time we reach Retrieval, the system has already generated notifications and, in some cases, actions. So what’s left? Retrieval is about going back into the record of everything we’ve collected and prepared so we can ask the questions that weren’t part of the initial decision tree.
This is where investigations happen. An analyst may want to look beyond the alert that triggered the case and ask, “What else has this user done in the past 72 hours?” or “Has this IP address communicated with other devices inside the network?” Retrieval lets us explore the broader history, building timelines and filling in details that go beyond the original cluster of events that generated the alert.
It’s also where reporting comes into play. Managers and executives want visibility into trends: how many alerts occurred, what categories they fell into, and how the organization’s security posture has shifted over time. Retrieval provides the ability to run calculations and generate the kinds of reports that demonstrate progress, highlight risks, and justify investment.
In short, Retrieval is not about producing the first line of defense, that work has already been done. It’s about supporting investigations, forensics, and oversight. While this part of the process most resembles a data lake, in a SIEM it is just one piece of a much larger cycle. The value of Retrieval lies in giving us the ability to look back, ask new questions, and build understanding beyond the moment of detection.
Conclusion: Why the Stages Matter
Looking at the SIEM as a series of stages highlights an important truth: this is not just a log repository, it is a process. From collection to preparation, from analysis to routing, and finally to outbound and retrieval, each stage adds its own layer of value.
For a SIEM user, or someone evaluating SIEM technology, the stages matter because they show both the complexity of the system and the standards you should expect. A good SIEM doesn’t simply take in logs; it prepares them, analyzes them in context, and delivers results in ways that support both immediate response and long-term operations.
That is what turns raw data into security outcomes. By breaking the process into stages, we can see more clearly what a SIEM is supposed to do, where its strengths lie, and how it supports the daily work of detection, investigation, and response.



