The SIEM Beneath the AI Icing
What are the characteristics of a SIEM that make it a good match for AI workflows and AI in general?

In the rush to showcase AI-powered security, it’s easy to become enamored with the icing—LLMs that summarize alerts, auto-generate tickets, or even recommend actions. But as anyone who’s ever eaten cake knows, the icing may be delightful, but the bulk of the value—and the structure—comes from the cake itself. When it comes to AI-enabled cybersecurity, the cake is still the SIEM.
What makes a SIEM useful to AI? This is a key aspect to future of AI SIEMs. For we are not building a SIEM based on the needs of people, but on the needs of AI automation.
While many vendors are now bolting language models onto legacy systems, Fluency SIEM was built from the ground up with one goal in mind: enabling high-quality AI analysis. Its architecture doesn’t just accommodate AI—it elevates it. By delivering clean, structured, enriched data through a real-time pipeline, and by providing secure, on-demand context when needed, Fluency ensures that AI can think clearly, reason effectively, and deliver results that are accurate, relevant, and trustworthy.
This is what sets Fluency apart. The true benefit isn’t speed or cost—it’s quality. In security, precision matters. You don’t want AI that guesses; you want AI that understands. Fluency provides the environment where understanding is possible—by design.
Let’s look at the features that make Fluency uniquely capable of supporting AI workflows—not just as standalone components, but as part of a cohesive, AI-ready system:
- Pre-scored and grouped behavioral clusters
- Defined GenAi Workflows
- Supporting facts via Model Context Protocol (MCP)
- Enriched tags, peer insights, and reasoning scaffolding
- UEBA scoring and clustering
- Data transformation pipelines
- Defined SOC workflows and processes based on SOC Tiers
Pause here. Listing technology alone misses the point. These capabilities matter not simply because they exist—but because of how they’re used. To truly understand why Fluency’s design makes AI effective, we need to shift focus—from tools to process.
Reducing Volume to Improve Reasoning
Before AI can reason well, the data must be shaped into something it can understand. That starts with reducing the overwhelming volume of raw telemetry into something closer to intelligence. But volume reduction doesn’t mean throwing away important details—it means removing the noise while preserving the signal and its supporting context.
Every environment generates massive amounts of raw data: logs, flows, authentication events, DNS queries, alerts. Left unprocessed, this data is both too noisy and too costly for AI to interpret directly. That’s why Fluency’s real-time analytics pipeline is designed not just to transform and filter, but to structure, score, and cluster events into meaningful analytical units.
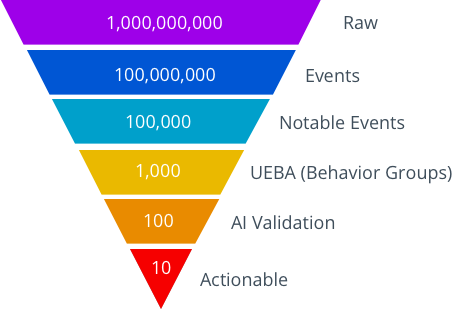
This is where a combination of scoring and UEBA clustering plays a critical role.
Unlike simple database grouping—which might bundle events by shared attributes—clustering in Fluency reflects actual behavioral relationships. It identifies key events that matter (such as a login from a new location), and supporting events that provide context (such as a device profile change or endpoint response). Together, they form a behavioral cluster: a coherent, enriched snapshot of what occurred, why it’s notable, and how it relates to other activity.
The purpose of clustering isn’t just to reduce volume—it’s to elevate clarity. And that clarity directly benefits AI reasoning.
In other systems, AI is asked to examine one alert and then guess what else might be related. In Fluency, those relationships are already established. The AI is handed a ready-to-analyze cluster—complete with relevant facts, supporting evidence, and risk scoring already applied.
This dramatically reduces token bloat and reasoning ambiguity. It lets the AI work with what matters, without losing the story behind the behavior. The results? Better decisions, faster conclusions, and fewer mistakes.
Reducing volume isn’t about cutting corners. It’s about sharpening focus.
From 42 to Understanding: Why Workflows Matter in AI Analysis
In The Hitchhiker’s Guide to the Galaxy, a supercomputer named Deep Thought is tasked with calculating the Answer to the Ultimate Question of Life, the Universe, and Everything. After seven and a half million years of computation, it finally produces an answer: 42.
But there’s a problem.
No one knows what the original question was.
This joke, now famous in tech and pop culture, illustrates a deeper truth in AI: an answer is only as useful as the question that shaped it. And in cybersecurity, where clarity can make the difference between confidence and confusion, that matters.
That’s why Fluency’s design revolves around structured workflows.
A workflow isn’t just a path to an answer—it defines the question being asked. It shapes the logic. It clarifies the scope. And most importantly, it ensures the AI is solving a well-formed problem, not blindly analyzing data with vague direction like “tell me if this looks bad.”
In the section above, we explored how Fluency reduces raw data into behavioral clusters and then evaluates those clusters for validity and actionability. But the real leap in intelligence happens when those evaluations are organized as workflow-based questions.
Each workflow presents a specific pattern or concern:
- Is this a suspicious login based on behavior?
- Is this an unfamiliar process executing on a critical endpoint?
- Is this user exhibiting privilege escalation?
When the AI engages through these workflows, it’s no longer guessing—it’s answering intentional, structured questions. That leads to better reasoning, more consistent decisions, and less ambiguity.
Filling the Gaps: How Context Enhances Workflow Reasoning
Of course, not every question can be answered directly from the data in the cluster. That’s where MCP (Model Context Protocol) comes into play.
Even with the best reduction and grouping, some questions still require additional context:
- Is this a first-time login for the user?
- Is this device assigned to an admin?
- Has this account recently changed behavior?
- Is this normal for this role, region, or time?
These answers can’t always be embedded into the cluster ahead of time—they must be retrieved on demand. MCP allows the AI to ask these missing-but-essential questions in real time, pulling back just the facts it needs to reason well, without running expensive searches or dealing with incomplete snapshots.
This is where Fluency’s second phase of enrichment shines—on-demand clarity for AI workflows. It bridges the gap between known signals and situational awareness, helping the AI ask the right questions—not just process what it’s been given.
In this way, Fluency doesn’t just calculate an answer—it makes sure we understand the question.
On-Demand Context: The Missing Ingredient in Most SIEMs
We’ve talked about reducing raw data into meaningful clusters and about the importance of structuring those clusters within defined workflows. But to truly enable AI to operate like an analyst, you need more than good data—you need the ability to ask good questions at the right time.
That’s the role of MCP, or Model Context Protocol.
What Is MCP?
MCP is a secure, structured query interface built for AI workflows. It allows the AI—mid-analysis—to request specific facts it doesn’t yet have, and receive clean, normalized answers. These requests are typically lightweight but essential, such as:
- “Is this user a new user?”
- “Is this login location common for this account?”
- “Has this endpoint had unusual behavior in the last 72 hours?”
- “What peer group does this asset belong to?”
With MCP the AI gets direct access to data that requires authentication for access. And that is critical to high-quality reasoning. The AI determine the parameters based on the prompt. and then calls the MCP service to get the results. It then has the data to continue its reasoning.
Why does MCP enables real workflow reasoning as opposed to APIs? APIs require the caller to know the parameters needed. That is not always easy. AI can derive the parameters from the prompt. Making the data more accurate.
A workflow isn’t just a static playbook. In Fluency, it’s a live logic path. Each workflow presents a specific type of problem, and the AI is expected to interpret the clustered behavior in the context of that scenario.
But no cluster contains everything.
This is why MCP is essential to workflow design—it gives the AI just-in-time access to the rest of the story, letting it dynamically fill in knowledge gaps without inflating token size or pulling in irrelevant data.
Other systems might pre-load an enormous amount of information “just in case.” Fluency does the opposite: keep it lean, ask what’s needed. This results in better performance, more accurate prompts, and reasoning that stays tightly aligned with the problem at hand.
Why Traditional SIEMs Can’t Do This
Legacy SIEMs weren’t built with this kind of interactivity in mind. Most are query-based, database-heavy systems that require human analysts to pull data manually—or build complex dashboards and drill-downs.
They don’t support AI asking for a quick contextual fact and getting a clean answer in milliseconds.
They don’t support workflow-specific dynamic evaluation, where the AI adapts its logic depending on what it learns.
And they certainly don’t distinguish between enrichment for readability and enrichment for reasoning.
Fluency does.
Why SIEM Architecture Determines AI Effectiveness
To understand what makes AI succeed in cybersecurity, it’s not enough to evaluate the model—you have to evaluate the system the model is sitting on. That system is the SIEM. And how the SIEM is architected determines whether the AI can reason or just react.
Let’s be clear: AI needs access to data. But how that data is accessed—and how workflows are structured—makes all the difference.
Many security products today attempt to “bolt on” AI by inserting it into SOAR-style playbooks, where each step is governed by hard-coded API calls. These playbooks execute conditionals, make static decisions, and treat AI as an add-on that fills in the gaps.
Yes, this approach works. But it misses the point.
What’s wrong with this approach is that it reduces AI to a helper inside a rigid machine, rather than letting AI be the reasoning engine. The logic remains hardwired—step-by-step—and the AI becomes little more than a language-flavored “if-then” processor. This constrains the AI’s potential and introduces brittleness into the system.
Soft Logic vs. Hard Logic
AI thrives on soft logic—the ability to weigh signals, evaluate context, and draw nuanced conclusions. Traditional SOAR systems rely on hard logic—binary decisions, strict sequences, and predefined thresholds.
This is covered in detail at How do AI Workflows differ from SOAR Playbooks?
Hard logic works well for known patterns, but it breaks down in uncertain, overlapping, or novel scenarios—the exact space where AI shines.
Fluency’s SIEM design embraces soft logic. Because it structures data around behaviors, not logs, and because it enables workflows to represent real-world questions, AI is empowered to explore ambiguity, not constrained by it.
The Impossible Travel Example
Take a common use case: impossible travel detection. Traditional systems calculate the geographic distance between two IP addresses. If the time between logins makes travel implausible, they raise an alert. But that’s hard logic. And it’s narrow.
When AI runs this evaluation on top of Fluency, it doesn’t just look at distance. It considers:
- Authentication method (was it MFA? Device-based?)
- Network type (is the IP from a business, cloud provider, or anonymizer?)
- Location quality (mobile vs. fixed, obfuscated vs. known)
- Recent behavior (has this user done this before?)
- Peer comparison (do others in this role travel like this?)
It doesn’t need a fixed rule—it builds a layered understanding.
This is what the right SIEM architecture enables. Because Fluency organizes data around identity, behavior, and context, AI can think fluidly. The system doesn’t force AI into a predefined decision tree—it gives it room to reason.
Stepping Back
When we step back and look at what makes AI work in a cybersecurity setting, it becomes clear that the success of AI isn’t defined by the brilliance of the model—but by the quality of the system that feeds it. The SIEM isn’t just a data source. It defines the flow, the context, the structure, and the questions the AI is being asked to answer. What we’ve explored isn’t a list of features—it’s a design philosophy: that the right foundation enables better reasoning, and that AI’s value is unlocked when the system around it is built with intention. From data reduction to behavioral clustering, from workflow-based logic to contextual enrichment, Fluency’s SIEM isn’t just compatible with AI—it’s what makes AI effective, reliable, and insightful.
AI is only as good as the environment it operates in. And in cybersecurity, that environment is the SIEM. Fluency was built not just to store data, but to understand it—and to give AI the conditions it needs to do the same. While others chase speed or scale, Fluency focuses on quality of analysis—because better understanding leads to better outcomes. The result is a system where AI isn’t tacked on, but thoughtfully integrated. Where answers aren’t just accurate, but relevant. And where every decision is rooted in a deep, contextual grasp of what’s actually happening. In the future of cybersecurity, the SIEM isn’t replaced by AI—it’s the reason AI can finally do its job.
Afterthought
Interested in seeing where SIEMs rank in developing AI SIEM: Grading AI SIEM



