Run Your SOC like an MSSP
MTTD and MTTR measure speed. They do not measure the effectiveness of the overall operation.

When people talk about measuring a SOC, the first metrics that usually come up are MTTD and MTTR. These appear in marketing material, but they only tell part of the story. They measure speed: how quickly something was detected or how quickly a response began. They do not measure the effectiveness of the overall operation. They fail to tell us the bottlenecks that are stopping us from addressing all the issues.
To manage a SOC, we need more than speed metrics. We need to understand the entire flow of work as it moves through the system. That requires a framework of milestones, which mark key points in the lifecycle of a case, and processes, which fill the gaps between those milestones. With that structure in place, we can measure not only how fast things happen, but also how they are done, who is doing the work, and where quality or cost issues arise.
This paper walks through that framework: first by defining the milestones, then the processes, and finally by discussing what metrics actually matter when evaluating SOC performance.
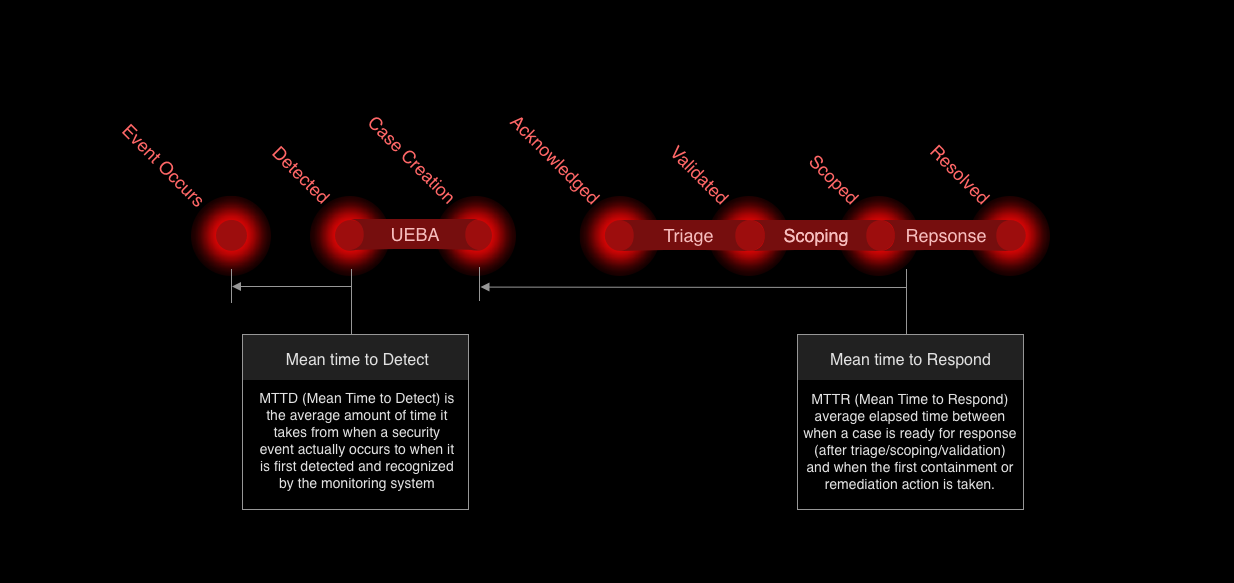
Milestones (points in time)
Each of these is a checkpoint where we can measure mean time to milestone. This means that for each milestones we will compare the timestamp the event occurred to when the milestone is met creating an MTTx metric.
- Event Occurs – the security event happens in reality (ground truth). This is our base timestamp.
- Detected – monitoring stack (SIEM, EDR, UEBA, IDS, etc.) raises an alert. (MTTD ends here)
- Case Created – system or automation generates a trackable record.
- Case Acknowledged – human or AI first touches the case.
- Case Validated – triage confirms this is a real, actionable issue.
- Case Scoped (Response Begins) – scoping defines affected assets/IoCs and the case is now actionable for containment/response. (MTTR starts here)
- Resolved – case is closed after remediation is executed. (MTRR ends here)
Note that Mean Time to Resolution (MTRR) is the average elapsed time between when a case becomes actionable (Case Scoped) and when the issue is fully resolved and closed in the SOC system. Hence, MTRR is the full duration of the response process, while MTTR is the speed of initiating response.
How Cases Impact Metrics
When we measure SOC performance, it’s tempting to think of every metric as tied neatly to a single event. But in reality, cases are rarely born out of just one event. A case is a collection of alerts and signals that together represent a potential security issue. This creates a challenge: if a case contains many events, which one do we measure against when calculating metrics like MTTD, MTTR, or MTRR?
To answer that, we have to define a key event, the specific event within the cluster that becomes the anchor for our measurements. The definition of this key event depends heavily on the type of system in use.
In a streaming system, identifying the key event is straightforward. Streaming analytics continuously maintain state and update risk scores in real time. The trigger is simply the event that pushed the behavior over the threshold, creating the detection. That trigger event gives us a precise timestamp to measure from, and every subsequent metric builds off of that anchor.
In contrast, a set-oriented system like a database-driven SIEM doesn’t maintain state across events. Instead, it runs periodic searches across collections of logs. In this model, it’s much harder to identify a key event. You can’t simply take the earliest event in the set (the minimum) or the latest (the maximum), because neither truly represents the tipping point. Analysts have to make a judgment call, often selecting a “critical event” such as the phishing email or the abnormal login that stands out as the likely cause for escalation. But this approach is inherently less accurate when auto\mated, the “key event” may occur much later than the original malicious activity that would have justified a case, making the derived metrics less reliable.
Streaming systems make that anchor explicit through trigger events, while set-oriented systems force us to approximate with key events.
Activities (intervals between milestones)
Unlike milestones, which measure when something happened, activities measure how the work was performed and by whom. In a SOC, three main processes dominate after case creation: triage, scoping, and response. For completeness I list the clustering (UEBA), but this processes of determining a case is normally only measured when case creation is not an aspect of the SIEM.
Each is a process that takes time to perform.
- Clustering (UEBA) – occurs between Event Occurs → Detected. (Analytics condense raw events into alerts.)
- Triage – occurs between Case Created → Case Validated. (Noise reduction, enrichment, decision-making.)
- Scoping – occurs between Case Validated → Case Scoped. (Determine assets/users affected, impact boundaries.)
- Response – occurs between Case Scoped → Resolved. (Containment, eradication, remediation.)
Triage
Triage begins the moment a case is created and continues until it is either validated or dismissed. This process is about deciding whether the case is real and actionable. It can close out a case immediately if the activity is a false positive or non-actionable issue. In that sense, triage has both a time component (how long it takes) and a result component (was the case closed?). The ownership of triage is pivotal to process improvement as it captures who performed the work: an analyst, an AI workflow, or an automated SOAR playbook. T
Scoping
If the case is not closed by triage, it moves into scoping. Scoping does not add data. Scoping extracts the properties present in the alerts that relate directly to the threat. These properties are referred to as the objects of interest (OOIs). These OOIs are in turn searched for in the logs to determine if other asset or entity has had interaction. This process allows us to see a much larger issue that may be occurring outside of the scope of the case.
Response
Once scoping is complete, the case is ready for action. This is the phase most MSSPs focus on the MTTR (Mean Time to Respond). For an MSSP, MTTR often marks the end of their responsibility, since remediation may be handed back to the customer. But for an in-house SOC, it’s just as important to measure MTRR (Mean Time to Resolution), the full duration until the case is fully closed.
From Metrics to Process Improvement
Defining milestones and processes gives us the framework for measuring SOC performance, but value comes from using these metrics to improve operations. Each metric tells us how long something takes, where in the workflow issues occur, and who is doing the work: analyst, AI, or SOAR. Every action has a cost. Moreover, the same step performed by automation, AI, or a human has very different costs. Tracking how the work is done shows where processes generate the most cost and where bottlenecks occur.
If workload is not tied to resources, the default reaction is to add more staff. Understaffing shows up as alert fatigue. Here poor management without process insight will blames the system. Measuring only speed misses the point. It does not matter how fast one ticket is handled if the SOC cannot keep up with all tickets and important issues are not addressed. Metrics show where processes are overloaded and where cases may not be properly addressed.
Volume alone does not explain resource use. A cost-based view shows where automation is effective, where human judgment is required, and where inefficiencies remain. For MSSPs, these metrics map directly to quality and profitability. For internal SOCs, they measure whether the organization can manage the problem.
What Metrics Matter
If the goal is to run an operations center like an MSSP, the point is not just cost or volume, it’s quality. Metrics give us the framework, but what we really want to measure is where the process fails. Failure is not only about whether a ticket moves through the stages, but whether it is handled correctly. Speed without accuracy is not success. A fast triage that misses a true threat is still a failure.
This is why quality sits alongside timing. Metrics such as MTTD, MTTR, or MTRR show how quickly work moves, but the real question is whether the work was done well. When a failure occurs, we need to know where in the process it happened. Did triage close cases incorrectly?Did response actions fall short? Metrics give us the ability to trace failure back to its point in the workflow.
That does not mean quality replaces metrics. The two work together. Defined processes and defined metrics are the foundation. Without them, you cannot evaluate the impact of changes or improvements. The saying holds true: you cannot improve what you do not measure. Metrics are the baseline; quality is the outcome.
Conclusion
Metrics are a core component of management. For MSSPs, they are central to daily operations. Metrics track quality of work, identify bottlenecks, highlight costs, and show how to grow and scale against the data under management. That is their business focus. For anyone running a SOC, there is value in adopting the same mindset: learning from professionals who depend on metrics to operate effectively.
It is important to understand that the commonly advertised metrics, MTTD and MTTR, are speed metrics. They measure how fast detection or response occurs, but speed is not the first concern. The first concern is quality: was the work done correctly? Too often, when data volume is high or bottlenecks form, tasks are dropped. The metrics show what was completed, but they do not show what was missed. This is why quality must come first. Metrics that highlight quality and cost provide the real insight. These are not always the front-line metrics, but they are the ones that expose failures. Once a failure is identified, the process can be evaluated, and only then can improvements in speed follow.
The lesson is that internal SOCs should model themselves after MSSPs, even if they operate on their own. Just as it makes little sense to build your own SIEM or intelligence platform from scratch, it makes little sense to improvise SOC management without defined metrics and processes. Companies exist that dedicate themselves to doing this well, and their practices are proven. Learning from those practices and applying them at the management level is the key to improvement. At the executive level, metrics support both the operational side of running the SOC and the higher-level goal of ensuring quality.



